R에서 새로운 컬럼 혹은 변수 생성하고 값 부여하기 II
앞선 예(https://spss-r.tistory.com/12)에서 새로운 컬럼 혹은 변수를 생성하는 법을 살펴보았습니다. 이때에는 기존의 변수를 활용하여 새로운 변수를 생성하였는데 여기에서는 기존의 변수 활용 없이 새로운 변수를 생성하는 법을 살펴보고자 합니다.
형태는 데이터명$변수명 <- 값 or 데이터명$변수명 <- "값"을 입력해주면 됩니다. 이를 살펴보기 위해서 new_column.csv 파일을 이용하였습니다. new_column.csv 파일을 temp라는 이름으로 불러왔습니다.
temp <- read.csv("new_column.csv", stringsAsFactors=FALSE, fileEncoding='UTF-8-BOM')을 입력해주면 됩니다. 이때 주의할 점은 new_column.csv 파일은 워킹디렉터리 안에 있다는 전제 하에 명령어를 입력한 것입니다.
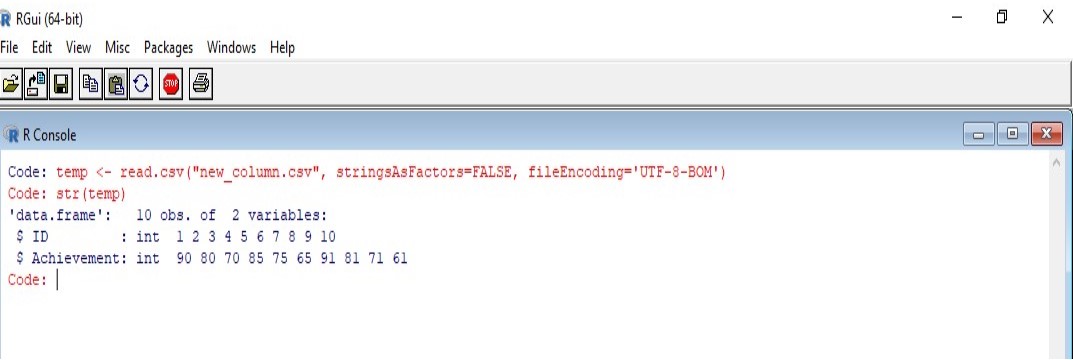
str(temp)를 입력하면 데이터에 몇개의 표본이 있고 변수는 몇개인지를 보여주며 또한 각각의 변수의 특성을 볼 수 있습니다. temp 데이터에는 10개의 표본(10 obs.)과 2개의 변수(2 variables)이 있으며 ID 변수와 Achievement 변수는 integer 특성을 가지고 있음을 알 수 있습니다.
그러면 학년을 나타내는 Grade 변수를 생성해보도록 하겠습니다. 그리고 학년은 5학년을 나타내는 5를 할당해보겠습니다. 이를 위해서는 데이터명$새로운 변수명 <- 변수값 을 입력하면 되는데 만약 값이 문자일 경우에는 "변수값"을 입력해주면 됩니다. 그래서 여기에서는 temp$Grade <- 5 를 입력해보았습니다.

그 결과 모든 ID에 Grade의 값이 5인 변수가 생성되어 있음을 확인 할 수 있습니다.
마지막으로 새로운 변수를 생성하되 변수 값이 문자형인 경우를 살펴보았습니다. 앞서 설명했듯이 변수값 대신에 "변수값"을 입력하면 됩니다.
이를 위해서 학교를 의미하는 변수 Sch를 생성하였고 값은 elementary를 입력하였습니다. 명령어는 temp$Sch <- "elementary"를 입력하였습니다.

지금까지 새로운 변수를 생성하는 법을 살펴보았습니다. 만약 기존의 변수를 활용하여 새로운 변수를 만들고 싶다면 https://spss-r.tistory.com/12를 참조하시면 됩니다.