-
R에서 특정 변수(혹은 특정 열)만 선택하기R/Contents 2022. 2. 9. 02:25
데이터분석을 하다보면 데이터에서 특정 변수(혹은 특정 열)만 선택해서 새로운 데이터로 만들어야 할 때가 있는데 여기에서는 특정 변수만 선택하는 방법을 살펴보고, 특정변수만 선택한 후 새로운 데이터로 만드는 방법을 살펴보고자 한다.
첫번째 방법은 패키지를 사용하지 않고, R에서 직접 변수를 선택한 후 새로운 데이터로 할당해주는 방법이다.
새로운 데이터 <- 데이터명[, c(변수위치번호,변수위치번호,변수위치번호)] 새로운 데이터 <- 데이터명[, c(변수위치번호:변수위치번호)] 새로운 데이터 <- 데이터명[, c(변수위치번호:변수위치번호, 변수위치번호)] 새로운 데이터 <- 데이터명[, c('변수명', '변수명', '변수명')]example_1.csv 파일에 보면 STDID, SCHID, GENDER, ENG, MATH, SCI, SocioEconomicStatus 변수들이 있다. 각 변수의 위치번호는 순서대로 STDID가 1, SCHID가 2, GENDER가 3... SocioEconomicStatus 변수는 7이 된다.
첨부된 예제 파일을 불러 온 후 변수의 위치번호를 한번 확인해보도록 하겠다.
ex <- read.csv("example_1.csv", stringsAsFactors=FALSE, fileEncoding='UTF-8-BOM') names(ex) str(ex)예제 파일을 ex라는 이름으로 불러온 후 names(ex)와 str(ex)를 실행해 보면 다음의 그림과 같은 결과를 얻을 수 있다.
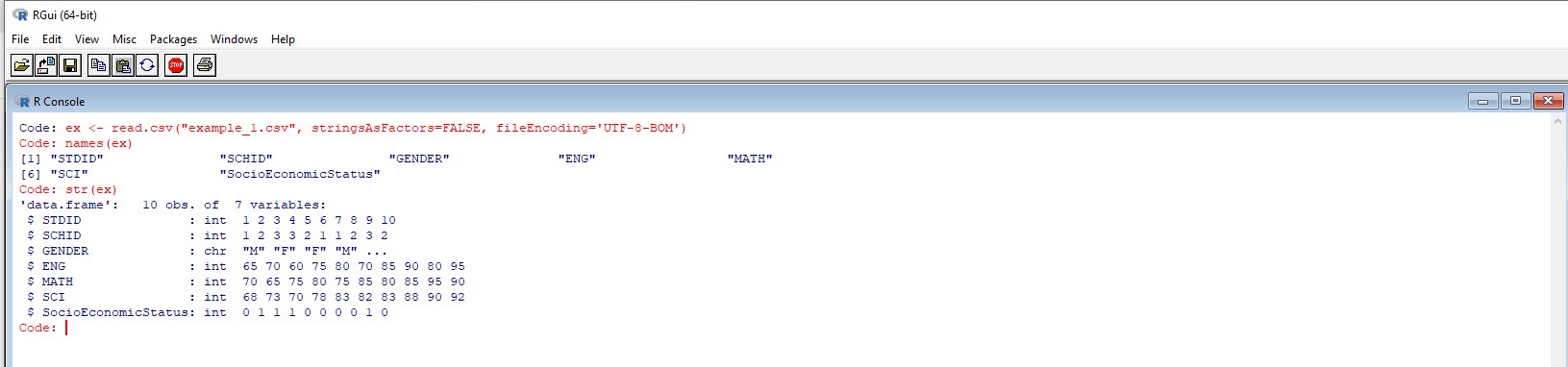
[그림1] names(ex)와 str(ex) 결과에서 보면 SCI변수의 위치번호가 6인 것은 쉽게 알 수 있고, MATH 변수의 위치번호는 SCI 이전이기 때문에 5라는 것을 알 수 있다.
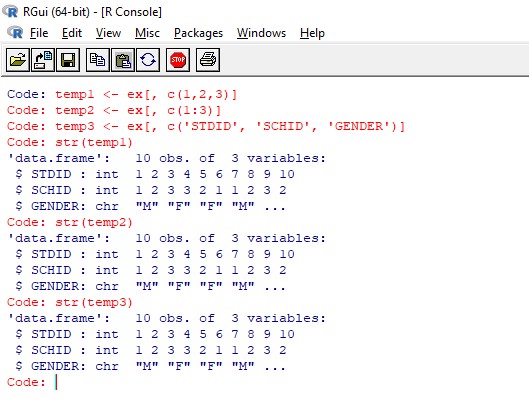
우선 연속된 변수 3개를 선택해 보았고 비교를 위해 각각을 temp1, temp2, temp3라는 이름의 데이터로 할당하였다.
temp1 <- ex[, c(1,2,3)] temp2 <- ex[, c(1:3)] temp3 <- ex[, c('STDID', 'SCHID', 'GENDER')]그 결과 동일한 변수가 선택 된 것을 확인 할 수 있고 아래 [그림2]와 같다.
[그림2] 연속 된 변수 3개 선택하기 만약 연속하여 있는 변수와 그렇지 않은 변수를 선택해야 하는 경우를 생각해보면, 여기서 STDID, SCHID, GENDER, 그리고 연속하여 있지 않은 SCI변수를 선택해 보았다.
temp1 <- ex[, c(1,2,3,6)] temp2 <- ex[, c(1:3,6)] temp3 <- ex[, c('STDID', 'SCHID', 'GENDER', 'SCI')]temp2를 보면 연속하여 있는 변수는 1:3으로, 그리고 연속하여 있지 않은 변수는 ,6 을 입력하였다. 결과를 보면
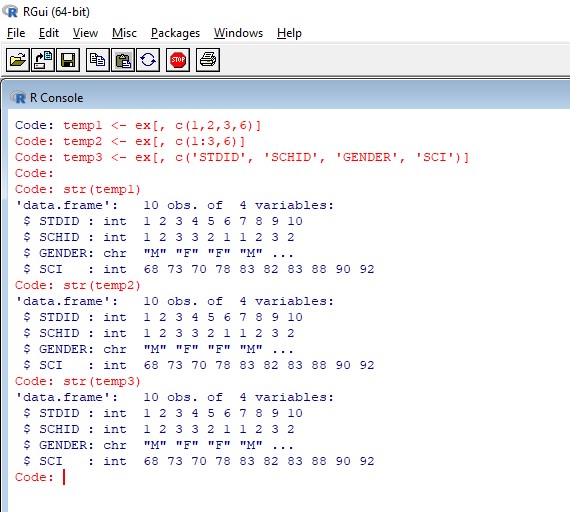
[그림3] 연속하여 있는 변수와 그렇지 않은 변수 선택하기 하나 더 예를 살펴보면, 연속하여 있는 변수인 STDID, SCHID, GENDER와 또 다른 연속하여 있는 변수 SCI, SocioEconomicStatus변수를 선택하고 싶다면 temp2에서와 같이 6:7를 입력해주면 된다.
temp1 <- ex[, c(1,2,3,6,7)] temp2 <- ex[, c(1:3,6:7)] temp3 <- ex[, c('STDID', 'SCHID', 'GENDER', 'SCI', 'SocioEconomicStatus')]그 결과는 다음의 그림과 같다.
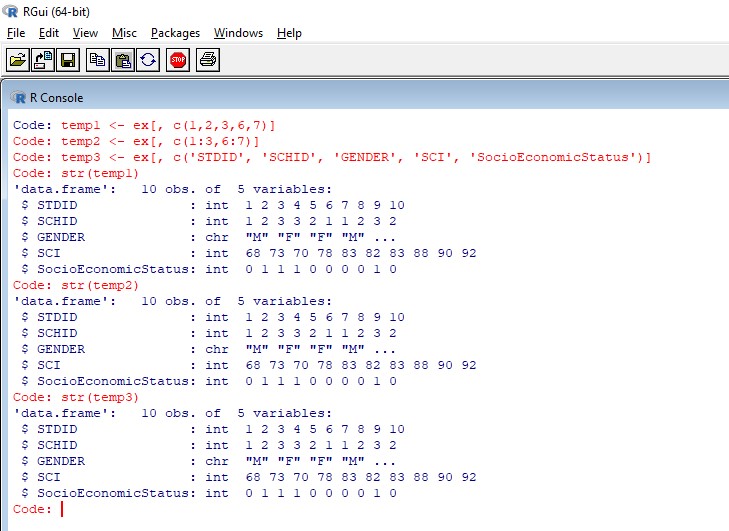
[그림4] 연속하여 있는 변수들 선택하기 지금까지는 R에서 직접 변수(혹은 컬럼)을 선택하는 방법이었고, 이제는 dplyr이라는 패키지를 사용해보았다.
기본 형태는 다음과 같다.
새로운 데이터 <- select(데이터이름, c(변수위치번호,변수위치번호,변수위치번호)) 새로운 데이터 <- select(데이터이름, c(변수위치번호:변수위치번호)) 새로운 데이터 <- select(데이터이름, c('변수명', '변수명', '변수명')) 새로운 데이터 <- 데이터이름 %>% select(변수명, 변수명, 변수명)[그림3]에서 활용한 변수를 이용해 한번 살펴보았다.
install.packages("dplyr") library(dplyr) temp1 <- select(ex, c(1,2,3,6)) temp2 <- select(ex, c(1:3, 6)) temp3 <- select(ex, c('STDID', 'SCHID', 'GENDER', 'SCI')) temp4 <- ex %>% select(STDID, SCHID, GENDER, SCI)그 결과는 [그림5]와 같다
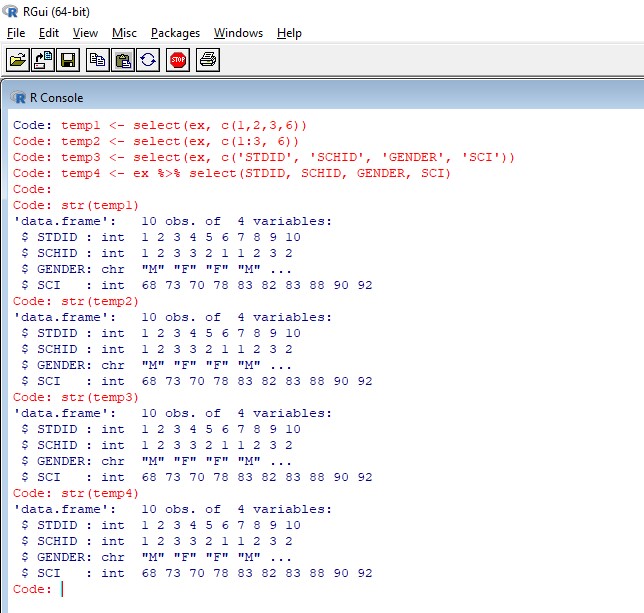
[그림5] dplyr을 이용하여 변수 선택하기 변수를 선택하여 새로운 데이터로 할당하는 방법에 대해서 살펴보았다.
'R > Contents' 카테고리의 다른 글
scatter plot - 산점도 그래프 (0) 2023.10.22 수열생성(벡터생성) (0) 2022.04.17 [R] 변수명 변경하기 (0) 2021.10.18 R 설치하기 (0) 2021.06.12 R에서 새로운 컬럼 혹은 변수 생성하고 값 부여하기 II (0) 2020.05.16